Pandas 读取 MySql 数据
1. 前言
上节课我们讲述了 Pandas 解析 TXT 文件,CSV 文件以及 Excel 文件数据,主要涉及到了两个函数 read_csv() 函数和 read_excel() 函数,并详细讲解了对应函数中常用的参数设置。
那 MySQL 作为数据记录和处理的常用工具之一,我们如何用 Pandas 进行 MySQL 数据的解析呢?本节课我们首先讲述 PyMySQL 库进行 MySQL 数据库的连接,然后讲述 Pandas 对 MySQLl 数据库的读取。
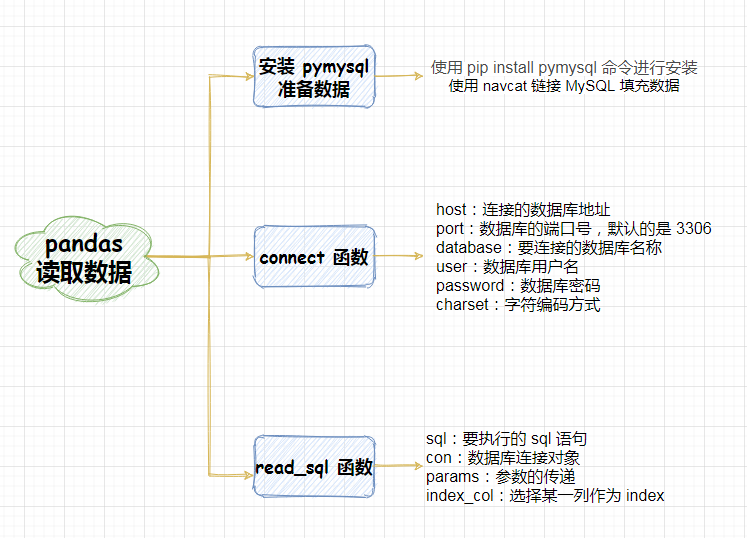
2. 安装 PyMySQL 库
PyMySQL 库是用于连接 MySQL 服务器的一个库,对应的是 Python3.x 的版本,如果是 Python2 要使用 MySqlDb 库。我们在使用 PyMySQL 之前要确保已经安装了该模块,下面我们介绍一下如何安装 PyMySQL 库。
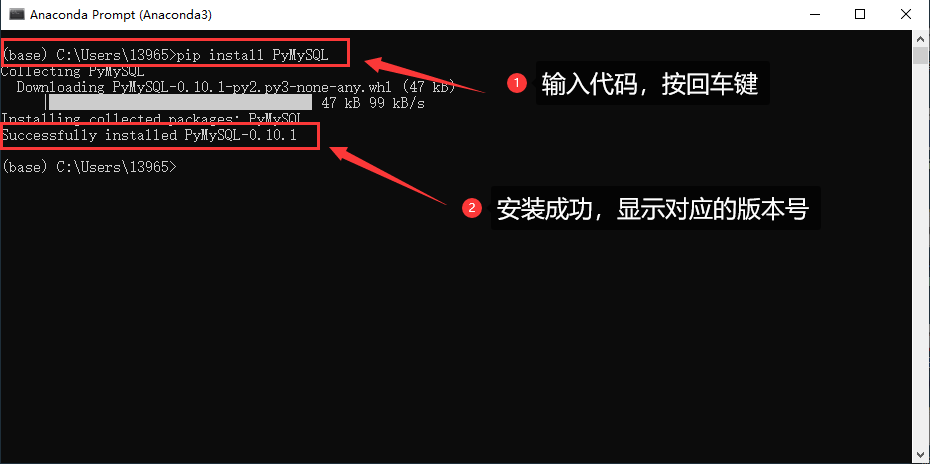
打开我们的 Anaconda 文件下的 Anaconda Prompt 工具,然后在命令窗口中输入命令行:pip install PyMySQL 接着按回车键,可以看到安装进度,最后显示 Successfully… 表示安装成功:
3. 准备数据文件
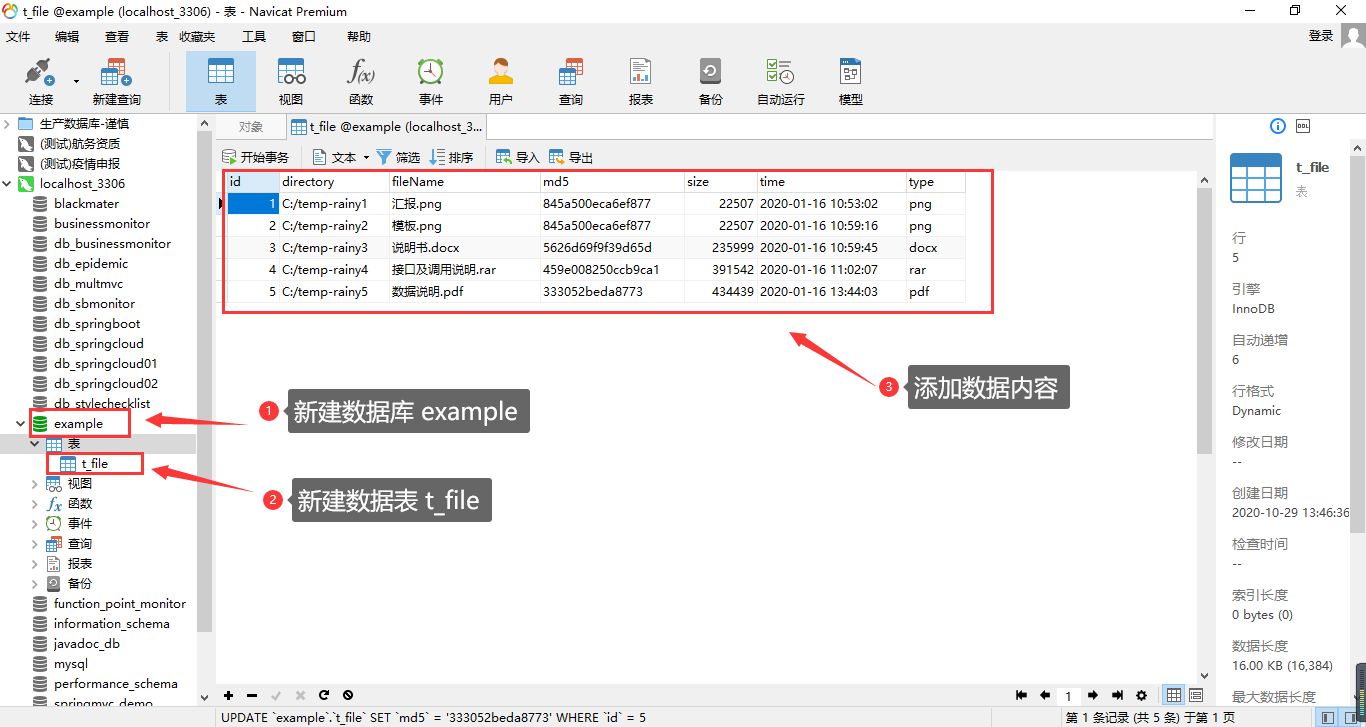
首先我们在 Navicate 数据库可视化管理工具中,新建数据库 example ,然后在该数据库中新建数据表 t_file (该表是文件管理数据表),在里面我们已经准备了一些数据:
4. PyMySQL 库的使用
4.1 导入 PyMySQL 库
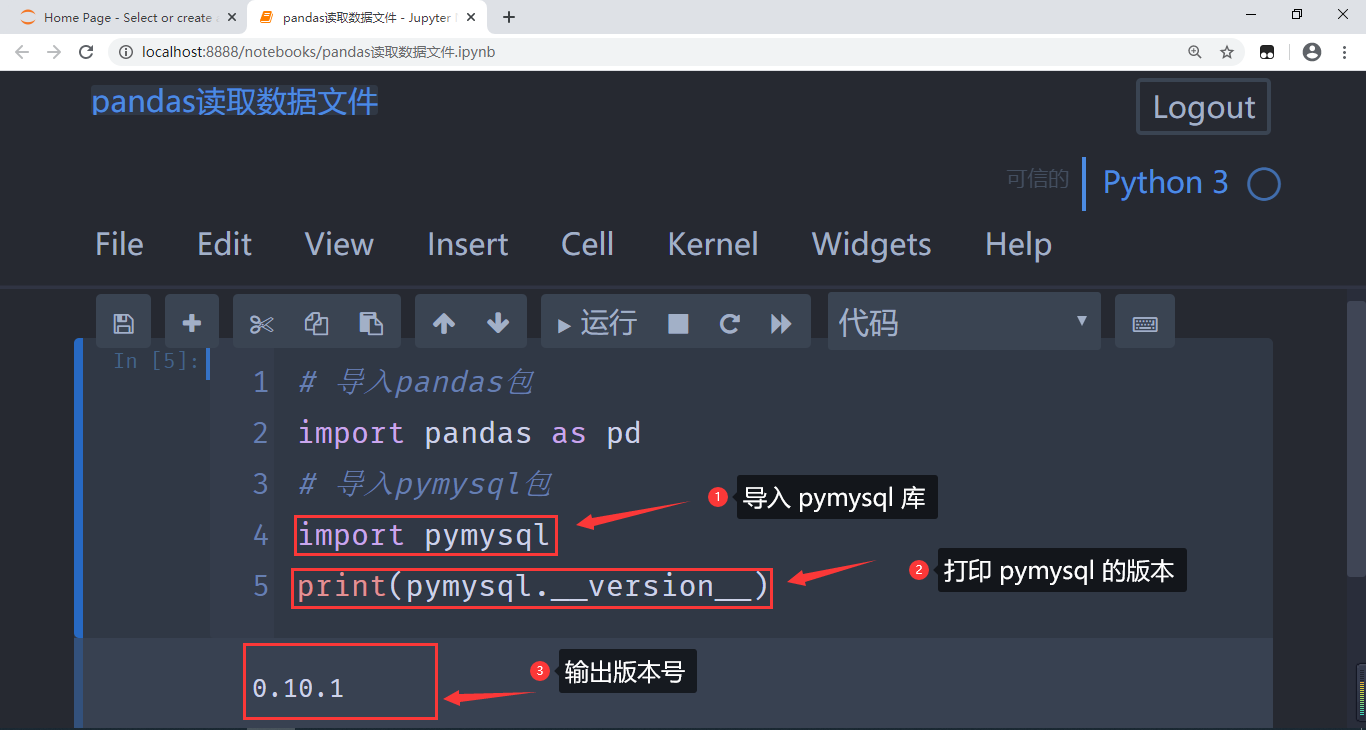
打开我们的 Notebook 工具,创建新的 Python 工作文件,通过 import pymysql 在程序中导入PyMySQL 库:
4.2 connect() 函数
PyMySQL 库中的函数 connect() 用于连接数据库,返回的对象是一个数据库连接对象,下面我们列举出了该方法常用的参数介绍:
| 参数名称 | 描述 |
|---|---|
| host | 连接的数据库地址 |
| port | 数据库的端口号,默认的是 3306 |
| database | 要连接的数据库名称 |
| user | 数据库用户名 |
| password | 数据库密码 |
| charset | 字符编码方式 |
下面我们通过代码用 connect() 方法来连接我们刚才建立的 example 数据库:
# 导入pandas 和 pymysql 包
import pandas as pd
import pymysql
# 返回一个 Connection 对象
db_conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='****',
database='example',
charset='utf8'
)
print(db_conn)
# --- 输出结果 ---
<pymysql.connections.Connection object at 0x000002C6F1D4F8E0>
输出解析 :通过输出结果可以看到,我们使用 connect() 函数,连接 MySQL 数据库,返回的是个 pymysql.connections.Connection 数据库连接对象,通过该对象我们后面可以进行对数据库的操作 。
5. Pandas 解析 MySql 数据
上面我们通过 PyMySQL 库建立了 MySQL 数据库连接对象,接下来我们将通过 Pandas 进行 MySQL 数据的解析。
5.1 read_sql() 函数
该函数主要从数据库中读取数据帧,里面提供了一些参数可以设置,下面列举常用的几个参数:
| 参数名称 | 描述 |
|---|---|
| sql | 要执行的 sql 语句 |
| con | 数据库连接对象 |
| params | 参数的传递 |
| index_col | 选择某一列作为 index |
参数 sql 和参数 con
我们首先通过代码演示这两个参数的设置,读取 example 数据库中的 t_file 数据表数据:
# 导入pandas 和 pymysql 包
import pandas as pd
import pymysql
# 返回一个 Connection 对象
db_conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='0508',
database='example',
charset='utf8'
)
# 执行sql操作
sql="select * from t_file"
pd.read_sql(sql,con=db_conn)
# --- 输出结果 ---
id directory fileName md5 size time type
0 1 C:/temp-rainy1 汇报.png 845a500eca6ef877 22507 2020-01-16 10:53:02 png
1 2 C:/temp-rainy2 模板.png 845a500eca6ef877 22507 2020-01-16 10:59:16 png
2 3 C:/temp-rainy3 说明书.docx 5626d69f9f39d65d 235999 2020-01-16 10:59:45 docx
3 4 C:/temp-rainy4 接口及调用说明.rar 459e008250ccb9ca1 391542 2020-01-16 11:02:07 rar
4 5 C:/temp-rainy5 数据说明.pdf 333052beda8773 434439 2020-01-16 13:44:03 pdf
输出解析 :我们通过 sql 语句设置数据库操作语句,这里我们是查询 t_file 的所有数据,参数 con 中我们传入了 PyMySQL 库创建的 db_con 数据库连接对象。通过输出结果可以看到,查出了 t_file 中的数据内容。
参数 params
该参数用于我们执行 sql 中参数的配置:
# 导入pandas 和 pymysql 包
import pandas as pd
import pymysql
# 返回一个 Connection 对象
db_conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='0508',
database='example',
charset='utf8'
)
# 执行sql操作
sql = "select * from t_file where id = %s"
pd.read_sql(sql,con=db_conn,params=[2])
# --- 输出结果 ---
id directory fileName md5 size time type
0 2 C:/temp-rainy2 模板.png 845a500eca6ef877 22507 2020-01-16 10:59:16 png
输出解析:我们 sql 查询语句中设置了 id 的参数条件,在 read_sql() 函数中我们通过 params 参数设置了 id 的条件为 2,因此看到我们的数据结果,正是我们数据库中 id=2 的数据行。
参数 index_col
通过该参数的设置,某一列指定为行索引。
# 导入pandas 和 pymysql 包
import pandas as pd
import pymysql
# 返回一个 Connection 对象
db_conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='0508',
database='example',
charset='utf8'
)
# 执行sql操作
sql = "select * from t_file"
pd.read_sql(sql,con=db_conn,index_col="type")
# --- 输出结果 ---
id directory fileName md5 size time
type
png 1 C:/temp-rainy1 汇报.png 845a500eca6ef877 22507 2020-01-16 10:53:02
png 2 C:/temp-rainy2 模板.png 845a500eca6ef877 22507 2020-01-16 10:59:16
docx 3 C:/temp-rainy3 说明书.docx 5626d69f9f39d65d 235999 2020-01-16 10:59:45
rar 4 C:/temp-rainy4 接口及调用说明.rar 459e008250ccb9ca1 391542 2020-01-16 11:02:07
pdf 5 C:/temp-rainy5 数据说明.pdf 333052beda8773 434439 2020-01-16 13:44:03
输出解析 :程序中我们通过设置 index_col=“type” ,指定字段文件的类型 (type) 作为我们数据行的索引,这里可以看到输出结果,最左侧的一列正式我们的 type 数据列,如果不指定 index_col ,默认的行索引是从0开始进行序号递增编排。
3. 小结
以上就是我们通过 Pandas 读取 MySql 数据库数据的基本操作,本节课程我们主要学习了 PyMySQL 库进行数据库连接对象的创建,然后用 Pandas 中的 read_sql() 函数进行数据库数据的解析,以及该函数中几个常用的参数。本节课程的重点如下:
- PyMySQL 库的安装和数据库连接函数 connect() 的使用;
- Pandas 库中 read_sql() 函数的使用和里面常用的参数。
Tips :想要学习更多Pandas相关知识,可以点击
Pandas Pandas读取数据文件
Pandas Pandas数据结构Series
Pandas Pandas数据结构DataFrame
访问者可将本网站提供的内容或服务用于个人学习、研究或欣赏,以及其他非商业性或非盈利性用途,但同时应遵守著作权法及其他相关法律的规定,不得侵犯本网站及相关权利人的合法权利。
本网站内容原作者如不愿意在本网站刊登内容,请及时通知本站,邮箱:80764001@qq.com,予以删除。
